
渲染原理
篇幅较长,需赖心阅读
示例代码
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="style.css" rel="stylesheet">
<title>Critical Path</title>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg"></div>
</body>
</html>1. 构建对象模型
浏览器渲染页面前需要先构建 DOM 和 CSSOM 树
文档对象模型(DOM)
构建过程
- 转换:浏览器从磁盘或网络读取 HTML 的原始字节,并根据文件的指定编码(例如 UTF-8)将它们转换成各个字符
- 令牌化:浏览器将字符串转换成 W3C HTML5 标准规定的各种令牌,例如,
<html>、<body>,以及其他尖括号内的字符串。每个令牌都具有特殊含义和一组规则 - 词法分析:将令牌转换成定义了属性和规则的“对象”
- DOM构建:由于 HTML 标记定义不同标记之间的关系(一些标记包含在其他标记内),创建的对象链接在一个树数据结构内,此结构也会捕获原始标记中定义的父项-子项关系:HTML 对象是 body 对象的父项,body 是 paragraph 对象的父项,依此类推
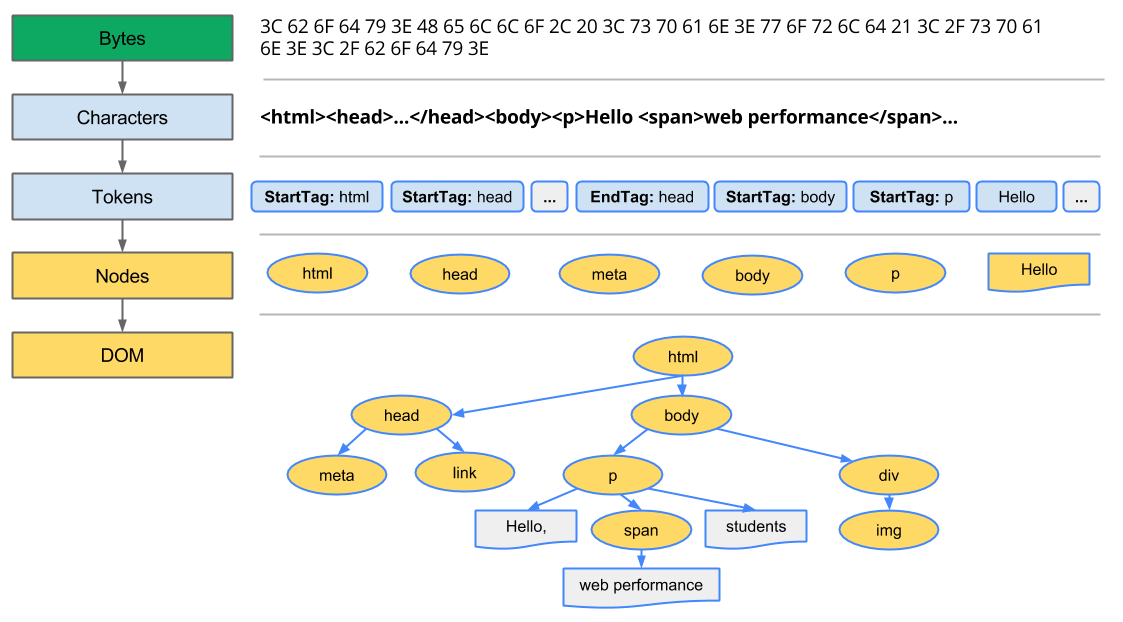
整个流程的最终输出是文档对象模型 (DOM),浏览器对页面做进一步处理时会用到它
浏览器每次处理 HTML 标记时,都会完成以上所有步骤:将字节转换成字符,确定令牌,将令牌转换成节点,然后构建 DOM 树。
CSS对象模型(CSSOM)
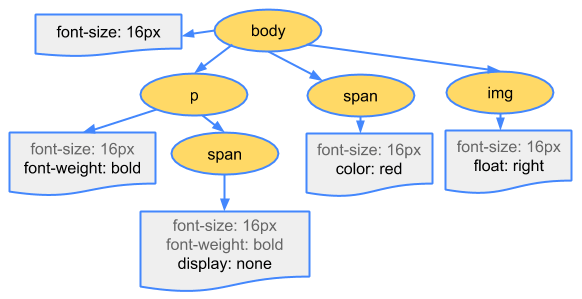
在浏览器构建我们这个简单页面的 DOM 时,在文档的 head 部分遇到了一个 link 标记,该标记引用一个外部 CSS 样式表:style.css。
body { font-size: 16px }
p { font-weight: bold }
span { color: red }
p span { display: none }
img { float: right }与处理 HTML 时的流程类似
CSS 字节转换成字符,接着转换成令牌和节点,最后链接为为一个“CSS 对象模型”(CSSOM) 的树结构内
 />
/>
 />
/>
小结
- 浏览器渲染页面前需要先构建 DOM树 和 CSSOM 树
- 构建流程:字节(Bytes) → 字符(Characters) → 令牌(Tokens) → 节点(Nodes) → 对象模型(Dom)
- DOM 和 CSSOM 是相互独立的数据结构
2. 渲染树构建
简介
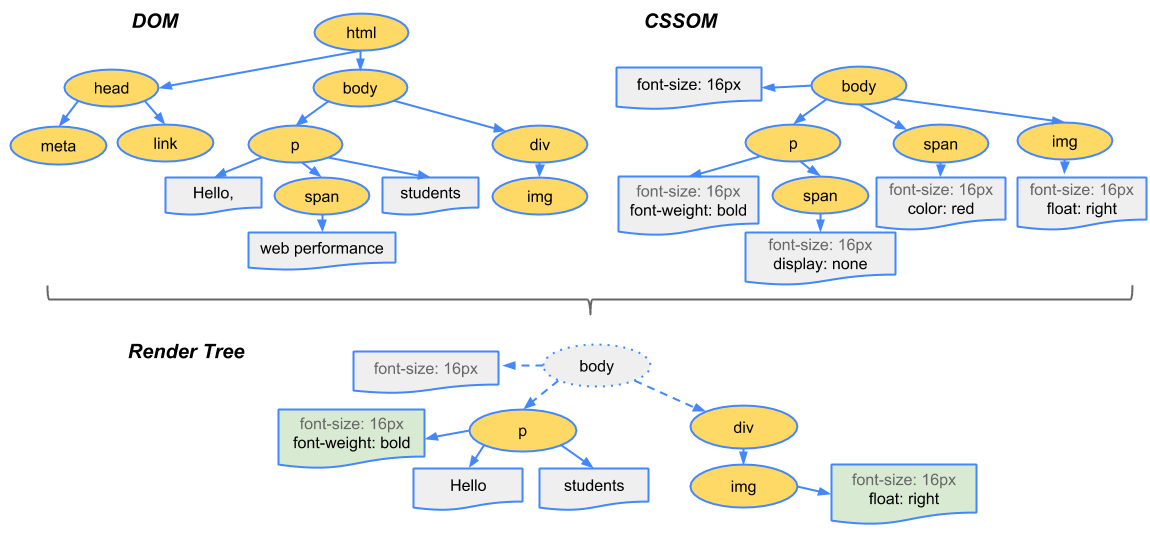
渲染树用于计算每个可见元素的几何信息,然后根据这些元素的几何信息绘制出屏幕上的实际像素
构建过程
浏览器将 DOM 数和 CSSOM 数合并成“渲染树”,包含页面上所有可见的内容,以及每个节点的所有 CSSOM 样式信息
 />
/>
- 从 DOM 树的根节点开始遍历每个可见节点
- 某些节点不可见(例如脚本标记、元标记等--title,meta,link)
- 某些节点通过 CSS 隐藏,因此在渲染树中也会被忽略(display:none)
- 对于每个可见节点,为其找到适配的 CSSOM 规则并应用它们
小结
- DOM 树和 CSSOM 树合并生成渲染树
- 渲染树只包含渲染网页所需的节点(可见节点)
3. 回流与重绘
回流
也有 “布局”,“重排”等叫法
根据生成的渲染树,从渲染树的根节点开始进行遍历,计算每个节点的几何信息(在设备视口内的确切位置和大小)
输出是一个“盒模型”,它会精确地捕获每个元素在视口内的确切位置和尺寸:所有相对测量值都会转换为屏幕上的绝对像素
重绘
也叫 “绘制”或“栅格化”
经过生成的渲染树和回流阶段,得到了所有可见节点具体的几何信息与样式,然后将渲染树的每个节点转换成屏幕上的实际像素
总结
1. 解析HTML-构建DOM
浏览器解析接收到的 HTML ,并构建出 DOM 树
- 在网络中传输的内容其实都是0和1这些字节数据。当浏览器接收到这些字节数据以后,会将这些字节数据转换为字符串
- 将这些字符串通过词法分析转换为标记(token),这一过程在词法分析中叫做标记化(tokenization)
- 标记转换为 Node,根据不同 Node 之前的联系构建为一棵 DOM 树
- 在解析 HTML 文件的时候,当遇到 CSS 和 JS 文件,这时候浏览器也会去下载并解析这些文件,此时就会存在阻塞解析/渲染的问题
2. 解析CSS-构建CSSOM
解析样式表,构建出 CSSOM 树
在这一过程中,浏览器会确定下每一个节点的样式是什么(这一过程其实是很消耗资源的,因为样式你可以自行设置给某个节点,也可以通过继承获得),于是会递归 CSSOM 树,然后确定具体的元素到底是什么样式
因此:
- 尽可能的避免写过于具体的 CSS 选择器
- 对于 HTML 来说也尽量少的添加无意义标签,保证层级扁平
3. 合并DOM/CSSOM-生成渲染树
生成 DOM 树和 CSSOM 树之后,就会将这两棵树组合为渲染树
渲染树只会包括需要显示的节点和这些节点的样式信息
不显示的节点
- css:display:nonoe
- 标签:script,link,meta等等
4. 回流
根据生成的渲染树,从渲染树的根节点开始进行遍历,计算每个节点的几何信息(在设备视口内的确切位置和大小)
5. 重绘
经过生成的渲染树和回流阶段,得到了所有可见节点具体的几何信息与样式,然后将渲染树的每个节点转换成屏幕上的实际像素